����Ŀ������
���������������ڿ�������ƽ̨��Ŀ��һ�����Ƶ��ȵ����ͼ���ƽ̨�����Ի��õ���ͬ���Ʒ����̵ļ���ʵ�������������簢���Ƶ�ECS������ѷ��EC2���߹ȸ��Ƶ�compute engine�ȣ�ͬʱҲ������Щ����ʵ��֮��������ݴ��䡣
������Щ������֮��Ĵ����ٶ�ͨ���Dz�ͬ�ģ���ʹ��ͬһ���Ʒ������ڵIJ�ͬ���������֮�䴫�����ݣ�����Ҳ��������ͬ��
����������Ҫ����Щ������֮��Ĵ����ٶȽ��в������Թ����Ƚ��̷�������ʹ������ݡ�
�����ܽ������������ʵ��������3��Ҫ��
�����Բ�ͬ�����ڵ��Ʒ�������TCP/UDP�����ٶȽ��м�⡣
�����������������IJ��٣�Ҳ����˵��̨�������ڲ��ٵ�ʱ��������������������С�
������̨������֮����Ҫ��Ч�ؽ����������ӡ�
���������3�����⣬��ʵ�������½��������
���������ṹ
����һ�ּ��������������������Ŀͻ��˺ͷ���ˣ�����Щ����֮�以���������в��١�
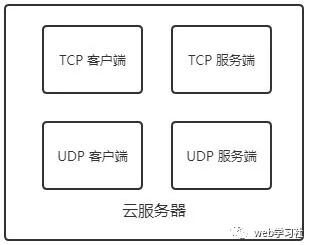
�����������ַ�ʽ�ڽ��̵Ĺ����Ϻ����׳������⣬��Ϊÿ�����̼�Ҫ�����Լ���״̬����Ҫ�����������̵�״̬��ͬʱһ������4������Ҳ�Ƚ��˷ѣ���Ϊ��ʵ��ÿ�β���ֻ����һ�����̹�����
�������Ը��õķ�ʽ�������ӽṹ����һ������������ͣ������ٵĿͻ�/������ӽ��̡�
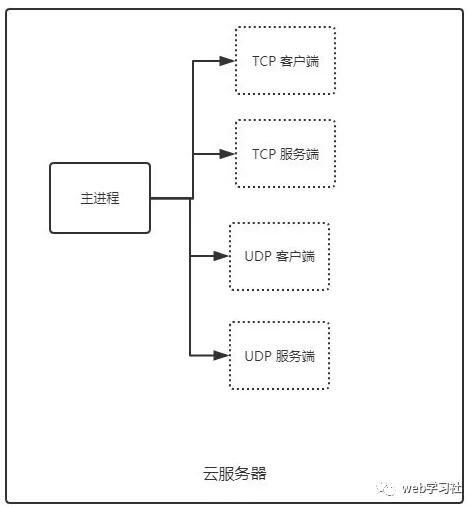
����������������Ч�ر�����Դ���˷Ѻ�������ͬʱ��������Ҳ���Լ��ɺܶ������ܣ���������ṩ REST API����¼��־�����ݲ��Խ���ȡ�
������ȻΪ�˷��㲿��ͳ�����ƣ����еĽ��̶��Dz����� Docker �����С�
����������������Ҫ������������ Docker ����������Ҫ���� Docker �� remote API ���������ṩREST API���в�����
��������ʵ��
������������
����TCP��UDP
��������Э����һ��һ���װ�����ģ���TCP��UDP����ͬһ�������Э�顣
��������TCPЭ����ǰ��˿����зdz����ã���ΪREST API����������HTTP(S)Э�����TCP���ϲ�Э�飬��UDPЭ������Ƶ����Ϸ�����ص�ҵ����ʹ��Ҳ�dz��ࡣ
����������һЩ��ͬ�㣺����ķ���Ϊ�ͻ��ˣ�����Ľ��շ���Ϊ����ˣ�����˺Ϳͻ��˿���˫��ͨ�š�
���������ǵIJ��ص���������TCP��ע���ȶ����ͻ��˺ͷ����֮����Ҫ��������֮����ܻ�������ݡ�
����UDP���ע���ٶȣ��ͻ��˲���Ҫ�ͷ���˽������Ӽ���ֱ�ӷ������ݣ�������������ٶ�̫��������粻�ȶ����ܻ���ɶ��������¶Է����յ����ݲ��ֶ�ʧ��
�������ٹ���
�������õ������в��ٹ�����iperf��speedtest�����֮��ѡ���˹��ܸ�ǿ���iperf��
����iperf��һ���Ƚ�����IJ��ٹ��ߣ�֧��TCP��UDPЭ�飬������ͨ���������ƶ��������ݴ�С������������ߴ���ʱ�䣬�Լ��������ĸ�ʽ��
������������ǰ��UDPЭ������ԣ����ٻ����鷳һЩ����Ҫ�ҵ����ʵĴ�����
�������簴��1Gbps���ٶȷ������ݣ���������70%�Ͱ���10Mbps���ٶȷ������ݣ���������0����ô��������������Ҫ��Ļ��϶���ƫ���ں��ߡ�
������Ȼʵ����������Ƕ��ڶ�����Ϊ0������õģ������ڿ����̵ķ�Χ�ڲ�������ٶȴ��䣨���ݶ��˻������ش�����~����
���������ζ����Ҫ����ʵ������״�����ϵ����ͳ��ԡ�
������iperf��û����ô���ܣ�����UDP��һ������Ŷ��ڲ�������һ��UDP���乤�ߣ����ҵ�����Ĵ����ٶȡ�
����������
����Ҫ��֤������ֻ��Ҫ��֤����ʱû����������ռ�ô������ɡ�
�����������ǿ�������һ̨��������ռʽ�����������в��ٳ������������Dz��ٳ���Ľ��̲�̫����ռ�ô������������������������������ٵ��ӳ���
����������Ҫ���ӳ���֮���ǻ������У������ǻ�����ڵġ�
��������״̬���������ϾͿ���ʵ�֣���������ÿ���н���������ʱ��״̬��Ϊ”connecting”��������ɺ���Ϊ”waiting”��ֻ����”waiting”״̬�²ſ��������µ��ӳ�����в��١�
����������ֻ�ǴӴ�����������ƣ������ȶ���׳�ij�����ԣ���û���������Ӳ�Կ��Ʒ�ʽ��
������ʱ��ʹ�������Ļ��Ϳ������ɰ쵽��
����������Ҫ���в��ٵĽ��̶���������������ͬʱ���������ƶ�ͳһ����ôһ���������bug��ͬʱ��������ӳ���ʱ��Docke r������ᱨ������֪�������Ƴ�ͻ���Ӷ�����ʧ�ܡ�
������Ȼ���ַ�ʽҲ��һ���ķ��գ�������һ�����̲��ٹ����г�������û�а�ʱ�˳�����ô���������µIJ��٣�������Ҫ��Ҫ�趨һ����ʱʱ�䣬����һ��ʱ�������ֹͣ��ǰ�����ӳ���
����ͬʱ��������������˳�������ֹͣʧ�ܵĻ���ҲҪ���д�������ÿ�������������ʱ����м�飬��ʱ����δֹͣ���ӳ���
������ڵ�
������ڵ����Ƿdz����ֵ����⡣���������һ��ʱ����ͬʱ�ڶ���Ʒ�����������������ٳ�����α�֤��������Ľ��в����أ�
����Ҫ���������⣬��˼��һ����Щ�����⣺
������һ��ʱ���ڣ���ξ�����Щ�Ʒ���������������ӳ�����Щ�Ʒ����������ͻ����ӳ����أ�
�����������“��-��”ģʽ�Ļ���Ҫ����һ�����Ľڵ������п��ƣ�����������ȱ��ܶ࣬����Ҫ��һ��ȱ�������ij���ڵ������Ľڵ���ͨ����ô��������������ڵ�ͨ�ŵĻ��ᣬ��ʱ���������ڵ�֮�����糩ͨ��
����ͬʱ���Ľڵ�������ڵ�֮��Ҳ���ڶ�ڵ�ͨ�ŵ����⡣
�����ܶ���֮���ַ�ʽ��ͨ�ŵijɱ�̫�ߣ��������ͻ��˴���������Ҫ���м价��̫�࣬�����׳������⡣
�������Լķ�ʽ�����Ʒ�����֮�以������������Ӧ��
���������Ļ������������Ҫ��Ϊ����ģ�飬һ��ģ��������Ӧ��������˿ڡ����������������
������һ��������ѯ�����ٶ��в��������������ͻ��������������ӡ�
�����������̴������£�
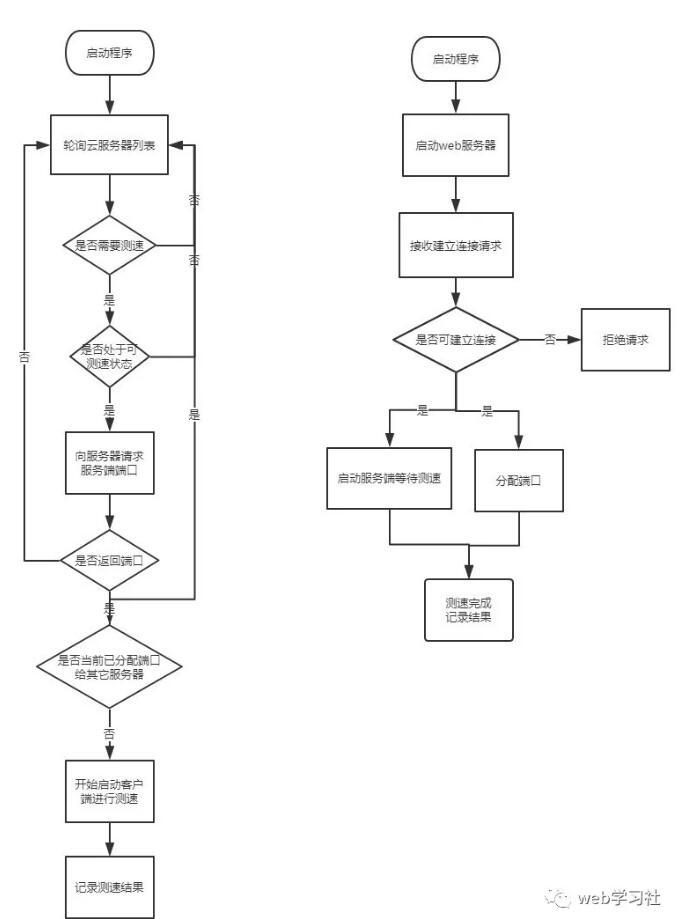
�������ִ�����ʽ����һ�ּ�����������������Ʒ�����֮�以��������в��ԣ����˫������ʱ��һ�£���ô�ͻ�ͬʱ���Է�����˿ڣ�Ȼ��ͬʱ�ܵ��Է�����Ķ˿�֮���ַ�������������Ƿ������ӡ�
�������dz��������ƽ���“����”��״̬��
����������������Ĵ�����ʽ��ʹ��ʱ�������¼�������ʱ�̣�˫��ͨ��ʱ������Ⱥ��������Ƿ������ͻ��˻����ˡ�
������ʹ�����˵��������——˫��ʱ�����ͬ����ôͨ����ʱ���ջ��߷���Ϣ�ͷŶ˿���������һ�����ӡ�
�����������µĴ���
����������ָ�������粻�ȶ����ߴ�����С�������
������������Ĵ�����ʽԭ���Ͼ����ز⣬���ǹ����ز��м�����Ҫע��ĵط���
�������ڴ�����С�������Ҫ���Ǽ�С�������ݵ�����Ա�֤���ƶ��ij�ʱʱ������ɲ��١�
�������ڲ���ʧ�ܵ���������жϲ��ز⣬ͬʱ���ز���������������ز⡣
�����ز�ʱ�����ÿͻ��������˽��л������ԣ�ͨ����һ�������ز��ʵ�֡�
�����ܽ�
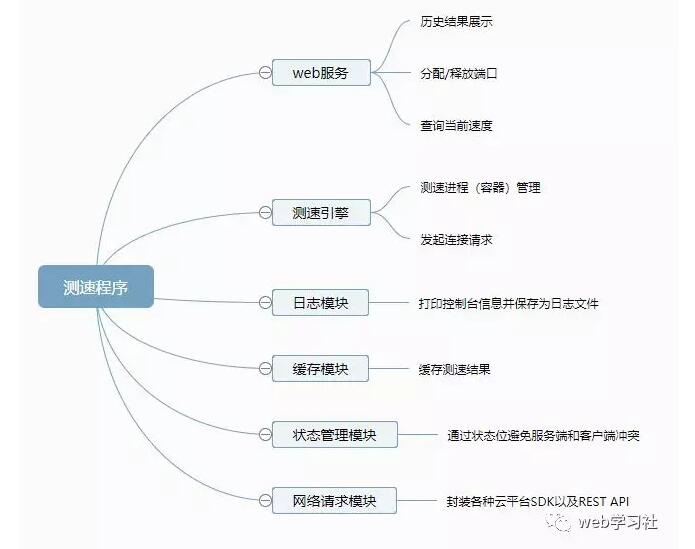
��������ṹͼ���£�
�����ܶ�ʱ��ʵ��һ�����ܲ������ѣ�����Ҫ�ѹ���ʵ�ֺ�ȴ��һ�������¡�
������Ȼ������ʵ������ֻ�Ǽĵ��ò��ٹ��߾Ϳ��Եõ����������ʵ�ʳ����¿����Ի��úܵ͡�
��������û�ж���������ز���ƣ���ôżȻ�����綶���ͻ�Ӱ�쵽���ٽ����
�������û�п��ǵ���ڵ��������ӵ����⣬��ôʵ�������ڶ���Ʒ������Ͽ��ܻ���ɳ���������ٽ����ȷ�����⡣
����Ҫ��ô���ѹ���ʵ�ֺ��أ�
�����������������Ƿ���
��������˼ά�����統ǰ���֧��10��ҳ��û���⣬��ô���100����1000��������������⣿
��������˼ά������һЩ��������µĴ������ƣ������ڱ����жԳ�ʱ�Ĵ���������������Ĵ����ȡ�
ת����ע���� ����ת���ԣ���˼��Դ�� http://www.aseoe.com/show-31-1124-1.html